Lunch Time Python¶
28.10.2022: PyTorch¶
PyTorch is a free and open-source machine learning framework that was originally developed by engineers at Facebook, but is now part of the Linux foundation. The two main features of PyTorch are its tensor computations framework (similar to numpy) with great support for GPU acceleration and their support for neural networks via autograd.
Press Spacebar to go to the next slide (or ? to see all navigation shortcuts)
Lunch Time Python, Scientific Software Center, Heidelberg University
0 Why use PyTorch?¶

Source: Twitter
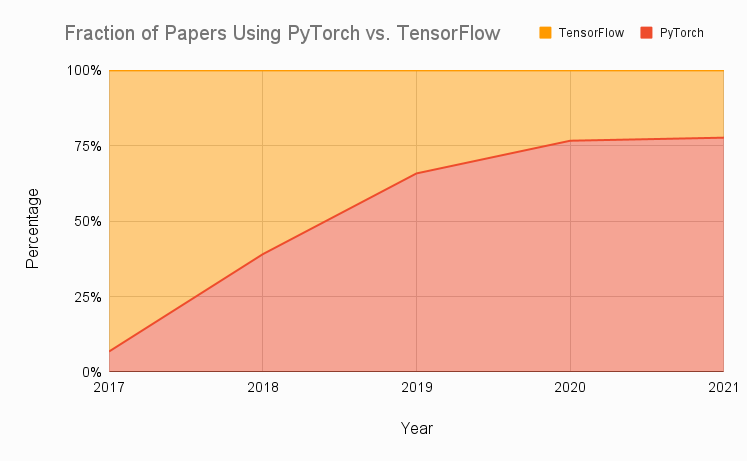
Source: Assembly AI
# first imports
import torch
from torch import nn # model
from torch import optim # optimizer
from torchvision import datasets, transforms # data and data transforms
from torch.utils.data import random_split, DataLoader # utilities
import numpy as np
import matplotlib.pyplot as plt
1 Tensors¶
# directly from data
data = [[1, 2], [3, 4]]
x_data = torch.tensor(data)
# from numpy array
np_array = np.array(data)
x_np = torch.from_numpy(np_array)
# from another tensor
x_ones = torch.ones_like(x_data) # retains the properties of x_data
print(f"Ones Tensor: \n {x_ones} \n")
x_rand = torch.rand_like(x_data, dtype=torch.float) # overrides the datatype of x_data
print(f"Random Tensor: \n {x_rand} \n")
Ones Tensor:
tensor([[1, 1],
[1, 1]])
Random Tensor:
tensor([[0.6420, 0.1056],
[0.4425, 0.8912]])
# use tuples to determine tensor dimensions
shape = (
2,
3,
)
rand_tensor = torch.rand(shape)
ones_tensor = torch.ones(shape)
zeros_tensor = torch.zeros(shape)
print(f"Random Tensor: \n {rand_tensor} \n")
print(f"Ones Tensor: \n {ones_tensor} \n")
print(f"Zeros Tensor: \n {zeros_tensor}")
Random Tensor:
tensor([[0.5408, 0.8277, 0.9690],
[0.7521, 0.8674, 0.0480]])
Ones Tensor:
tensor([[1., 1., 1.],
[1., 1., 1.]])
Zeros Tensor:
tensor([[0., 0., 0.],
[0., 0., 0.]])
# tensor attributes
tensor = torch.rand(3, 4)
print(f"Shape of tensor: {tensor.shape}")
print(f"Datatype of tensor: {tensor.dtype}")
print(f"Device tensor is stored on: {tensor.device}")
Shape of tensor: torch.Size([3, 4]) Datatype of tensor: torch.float32 Device tensor is stored on: cpu
# by default, tensors are created on CPU
# We move our tensor to the GPU if available
if torch.cuda.is_available():
tensor = tensor.to("cuda")
# indexing like numpy
tensor = torch.ones(4, 4)
print(f"First row: {tensor[0]}")
print(f"First column: {tensor[:, 0]}")
print(f"Last column: {tensor[..., -1]}")
tensor[:, 1] = 0
print(tensor)
First row: tensor([1., 1., 1., 1.])
First column: tensor([1., 1., 1., 1.])
Last column: tensor([1., 1., 1., 1.])
tensor([[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.]])
# joining tensors
t1 = torch.cat([tensor, tensor, tensor], dim=1)
print(t1)
tensor([[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.],
[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.],
[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.],
[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.]])
# This computes the matrix multiplication between two tensors. y1, y2, y3 will have the same value
y1 = tensor @ tensor.T
y2 = tensor.matmul(tensor.T)
y3 = torch.rand_like(y1)
torch.matmul(tensor, tensor.T, out=y3)
# This computes the element-wise product. z1, z2, z3 will have the same value
z1 = tensor * tensor
z2 = tensor.mul(tensor)
z3 = torch.rand_like(tensor)
torch.mul(tensor, tensor, out=z3)
tensor([[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.],
[1., 0., 1., 1.]])
# GPU via CUDA
# torch.randn(5).cuda()
# better (more flexible):
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
torch.randn(5).to(device)
tensor([-0.6897, 1.4091, 0.7586, 0.8636, -0.0978])
2 Datasets and DataLoaders¶
- datasets: stores the samples and their corresponding labels
- DataLoader: wraps an iterable around the Dataset to enable easy access to the samples
# import and split data
train_data = datasets.MNIST(
"data", train=True, download=True, transform=transforms.ToTensor()
)
train, val = random_split(train_data, [55000, 5000])
train_loader = DataLoader(train, batch_size=32)
val_loader = DataLoader(val, batch_size=32)
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Failed to download (trying next): HTTP Error 404: Not Found Downloading https://ossci-datasets.s3.amazonaws.com/mnist/train-images-idx3-ubyte.gz
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/train-images-idx3-ubyte.gz to data/MNIST/raw/train-images-idx3-ubyte.gz
0%| | 0.00/9.91M [00:00<?, ?B/s]
1%| | 98.3k/9.91M [00:00<00:11, 852kB/s]
2%|▏ | 229k/9.91M [00:00<00:09, 1.04MB/s]
5%|▍ | 492k/9.91M [00:00<00:05, 1.61MB/s]
10%|▉ | 983k/9.91M [00:00<00:03, 2.66MB/s]
19%|█▉ | 1.90M/9.91M [00:00<00:01, 4.56MB/s]
38%|███▊ | 3.74M/9.91M [00:00<00:00, 8.38MB/s]
74%|███████▎ | 7.31M/9.91M [00:00<00:00, 15.7MB/s]
100%|██████████| 9.91M/9.91M [00:00<00:00, 12.2MB/s]
Extracting data/MNIST/raw/train-images-idx3-ubyte.gz to data/MNIST/raw Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
Failed to download (trying next): HTTP Error 404: Not Found Downloading https://ossci-datasets.s3.amazonaws.com/mnist/train-labels-idx1-ubyte.gz
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/train-labels-idx1-ubyte.gz to data/MNIST/raw/train-labels-idx1-ubyte.gz
0%| | 0.00/28.9k [00:00<?, ?B/s]
100%|██████████| 28.9k/28.9k [00:00<00:00, 545kB/s]
Extracting data/MNIST/raw/train-labels-idx1-ubyte.gz to data/MNIST/raw Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
Failed to download (trying next): HTTP Error 404: Not Found Downloading https://ossci-datasets.s3.amazonaws.com/mnist/t10k-images-idx3-ubyte.gz
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/t10k-images-idx3-ubyte.gz to data/MNIST/raw/t10k-images-idx3-ubyte.gz
0%| | 0.00/1.65M [00:00<?, ?B/s]
6%|▌ | 98.3k/1.65M [00:00<00:01, 851kB/s]
20%|█▉ | 328k/1.65M [00:00<00:00, 1.51MB/s]
52%|█████▏ | 852k/1.65M [00:00<00:00, 2.88MB/s]
100%|██████████| 1.65M/1.65M [00:00<00:00, 4.03MB/s]
Extracting data/MNIST/raw/t10k-images-idx3-ubyte.gz to data/MNIST/raw Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz Failed to download (trying next): HTTP Error 404: Not Found Downloading https://ossci-datasets.s3.amazonaws.com/mnist/t10k-labels-idx1-ubyte.gz
Downloading https://ossci-datasets.s3.amazonaws.com/mnist/t10k-labels-idx1-ubyte.gz to data/MNIST/raw/t10k-labels-idx1-ubyte.gz
0%| | 0.00/4.54k [00:00<?, ?B/s]
100%|██████████| 4.54k/4.54k [00:00<00:00, 4.83MB/s]
Extracting data/MNIST/raw/t10k-labels-idx1-ubyte.gz to data/MNIST/raw
figure = plt.figure(figsize=(8, 8))
cols, rows = 3, 3
for i in range(1, cols * rows + 1):
sample_idx = torch.randint(len(train_data), size=(1,)).item()
img, label = train_data[sample_idx]
figure.add_subplot(rows, cols, i)
plt.axis("off")
plt.imshow(img.squeeze(), cmap="gray")
plt.show()

train_features, train_labels = next(iter(train_loader))
print(f"Feature batch shape: {train_features.size()}")
print(f"Labels batch shape: {train_labels.size()}")
img = train_features[0].squeeze()
label = train_labels[0]
plt.imshow(img, cmap="gray")
plt.show()
print(f"Label: {label}")
Feature batch shape: torch.Size([32, 1, 28, 28]) Labels batch shape: torch.Size([32])

Label: 9
3 Coding a neural network¶
# in theory easy via stateless approach
# import torch.nn.functional as F
# loss_func = F.cross_entropy
# def model(xb):
# return xb @ weights + bias
# print(loss_func(model(xb), yb), accuracy(model(xb), yb))
# gets messy quickly!
# define model via explicit nn.Module class
class MyModel(nn.Module):
def __init__(self):
super().__init__()
self.l1 = nn.Linear(28 * 28, 64)
self.l2 = nn.Linear(64, 64)
self.l3 = nn.Linear(64, 10)
self.do = nn.Dropout(0.1)
def forward(self, x):
h1 = nn.functional.relu(self.l1(x))
h2 = nn.functional.relu(self.l2(h1))
do = self.do(h2 + h1) # residual connection
logits = self.l3(do)
return logits
nn.Sequential is an ordered container of modules; good for easy and quick networks. No need to specify forward method!
# defining model via sequential
# shorthand, no need for forward method
model_seq = nn.Sequential(
nn.Linear(28 * 28, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Dropout(0.1), # often helps with overfitting
nn.Linear(64, 10),
)
# move model to GPU/device memory
model = model_seq.to(device)
Many layers inside a neural network are parameterized, i.e. have associated weights and biases that are optimized during training. Subclassing nn.Module automatically tracks all fields defined inside your model object, and makes all parameters accessible using your model’s parameters() or named_parameters() methods.
print(f"Model structure: {model}\n\n")
for name, param in model.named_parameters():
print(f"Layer: {name} | Size: {param.size()} | Values : {param[:2]} \n")
Model structure: Sequential(
(0): Linear(in_features=784, out_features=64, bias=True)
(1): ReLU()
(2): Linear(in_features=64, out_features=64, bias=True)
(3): ReLU()
(4): Dropout(p=0.1, inplace=False)
(5): Linear(in_features=64, out_features=10, bias=True)
)
Layer: 0.weight | Size: torch.Size([64, 784]) | Values : tensor([[ 0.0347, -0.0299, 0.0298, ..., -0.0337, 0.0265, 0.0007],
[ 0.0208, -0.0070, 0.0078, ..., -0.0119, 0.0299, 0.0156]],
grad_fn=<SliceBackward0>)
Layer: 0.bias | Size: torch.Size([64]) | Values : tensor([-0.0197, 0.0072], grad_fn=<SliceBackward0>)
Layer: 2.weight | Size: torch.Size([64, 64]) | Values : tensor([[-0.0790, 0.0397, -0.0087, -0.1046, -0.1221, -0.0238, -0.0441, 0.0490,
0.1074, -0.0225, -0.0746, 0.0060, -0.0338, 0.1168, 0.0531, -0.0845,
0.0320, 0.0072, -0.0015, -0.0047, -0.0365, -0.0926, -0.0062, -0.0747,
0.1145, 0.1180, 0.0756, 0.1017, 0.0144, -0.0053, 0.1086, -0.0534,
0.0947, 0.1087, 0.0845, 0.0908, -0.0695, 0.1082, -0.0404, -0.0439,
0.1121, 0.0480, 0.0050, 0.0688, -0.0179, 0.0907, 0.0349, -0.0017,
-0.0063, -0.0425, 0.0713, 0.0010, -0.0218, -0.1209, 0.1199, 0.0490,
0.1029, 0.0559, -0.0125, -0.0774, 0.0992, -0.1036, -0.0460, -0.0976],
[ 0.0429, 0.0061, -0.0164, -0.1153, -0.0685, 0.0051, -0.0878, -0.0925,
-0.0251, 0.1245, -0.0320, 0.0240, 0.0377, 0.0388, -0.0099, -0.0496,
-0.0839, -0.0620, 0.0460, -0.1009, 0.1044, 0.0724, 0.1019, -0.0714,
-0.0322, -0.0151, -0.0444, 0.0544, -0.0518, -0.0624, 0.0824, -0.1148,
-0.0564, 0.1046, 0.0264, -0.0628, 0.0432, 0.0798, 0.0796, 0.0640,
-0.0168, -0.0399, 0.0848, 0.0372, -0.1248, 0.0311, 0.0419, -0.1077,
-0.0982, 0.0319, 0.0614, -0.0648, -0.0410, 0.0702, 0.0862, -0.1198,
-0.0207, 0.1198, 0.1236, 0.0932, -0.1102, 0.0279, 0.0815, -0.0741]],
grad_fn=<SliceBackward0>)
Layer: 2.bias | Size: torch.Size([64]) | Values : tensor([-0.0522, 0.0198], grad_fn=<SliceBackward0>)
Layer: 5.weight | Size: torch.Size([10, 64]) | Values : tensor([[ 0.0706, -0.0530, -0.0515, -0.0981, 0.0143, -0.0883, 0.0672, -0.1249,
0.1093, -0.0138, 0.1070, 0.1133, -0.0596, 0.0304, -0.1191, 0.1028,
-0.0283, -0.0048, -0.0241, -0.1055, 0.0294, 0.1003, -0.0671, -0.0117,
0.0129, -0.0374, -0.0240, -0.0479, -0.0396, -0.0545, -0.0810, -0.0930,
0.0961, -0.0293, -0.1080, -0.0621, 0.0735, 0.0578, -0.1164, -0.0162,
-0.0857, 0.0115, -0.0634, -0.0542, -0.0510, 0.1111, -0.0535, 0.0124,
-0.0196, -0.0402, -0.0705, 0.0964, -0.0997, -0.0997, -0.0819, 0.0290,
-0.0211, 0.0381, 0.0259, 0.0020, -0.0196, 0.0596, -0.0998, 0.0777],
[-0.0149, -0.0765, -0.0319, 0.0842, 0.0050, -0.0668, -0.0912, 0.1135,
0.0445, -0.0556, -0.0656, -0.0159, 0.0894, -0.0866, 0.0993, 0.0185,
0.0007, 0.0907, -0.0891, -0.0615, -0.0959, -0.0425, -0.1176, 0.0465,
-0.0205, 0.0798, -0.0405, 0.0172, -0.0711, 0.0282, 0.0188, 0.0577,
-0.0696, 0.1047, 0.0186, -0.1095, -0.1037, -0.0071, 0.0981, 0.0416,
0.1130, 0.1014, -0.0334, 0.0932, -0.0074, 0.0135, 0.0303, 0.0069,
-0.1194, 0.0043, -0.1151, -0.0510, -0.1159, 0.0688, -0.0698, -0.0651,
0.0579, -0.0616, 0.0630, -0.1010, 0.0624, 0.0620, -0.1022, 0.0347]],
grad_fn=<SliceBackward0>)
Layer: 5.bias | Size: torch.Size([10]) | Values : tensor([ 0.0410, -0.0773], grad_fn=<SliceBackward0>)
# define loss function
loss = nn.CrossEntropyLoss() # softmax + neg. log
4 Backpropagation via Autograd¶
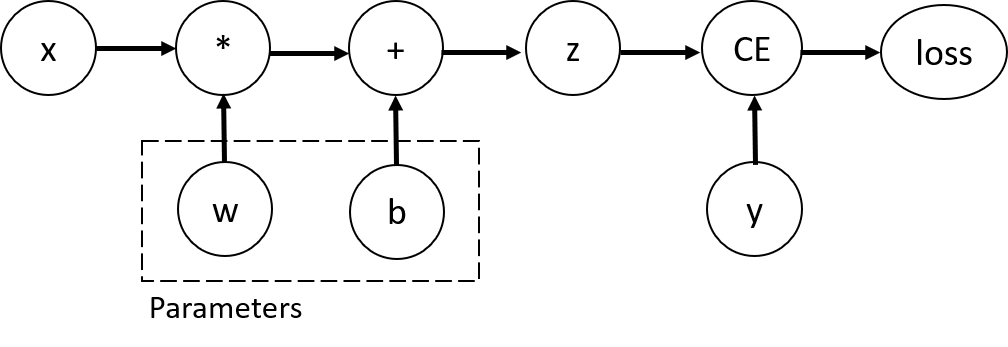
In a forward pass, autograd does two things simultaneously:
run the requested operation to compute a resulting tensor
maintain the operation’s gradient function in the DAG.
The backward pass kicks off when .backward() is called on the DAG root. autograd then:
computes the gradients from each .grad_fn,
accumulates them in the respective tensor’s .grad attribute
using the chain rule, propagates all the way to the leaf tensors.
5 Optimization of model parameters (training)¶
We define the following hyperparameters for training:
- Number of Epochs - the number times to iterate over the dataset
- Batch Size - the number of data samples propagated through the network before the parameters are updated (defined in train_Loader)
- Learning Rate - how much to update models parameters at each batch/epoch. Smaller values yield slow learning speed, while large values may result in unpredictable behavior during training.
lr = 1e-2
epochs = 5
# defining optimizer
params = model.parameters()
optimiser = optim.SGD(params, lr=1e-2)
Inside the training loop, optimization happens in three steps:
- Call optimizer.zero_grad() to reset the gradients of model parameters. Gradients by default add up; to prevent double-counting, we explicitly zero them at each iteration.
- Backpropagate the prediction loss with a call to loss.backward(). PyTorch deposits the gradients of the loss w.r.t. each parameter.
- Once we have our gradients, we call optimizer.step() to adjust the parameters by the gradients collected in the backward pass.
# define training and validation loop
# training loop
for epoch in range(epochs):
losses = list()
accuracies = list()
model.train() # enables dropout/batchnorm
for batch in train_loader:
x, y = batch
batch_size = x.size(0)
# x: b x 1 x 28 x 28
x = x.view(batch_size, -1).to(device)
# 5 steps to train network
# 1 forward
l = model(x) # l: logits
# 2 compute objective function
J = loss(l, y.to(device))
# 3 cleaning the gradients (could also call this on optimiser)
model.zero_grad()
# optimizer.zero_grad() is equivalent
# manually: params.grad._zero()
# 4 accumulate the partial derivatives of J wrt params
J.backward()
# manually: params.grad.add_(dJ/dparams)
# 5 step in the opposite direction of the gradient
optimiser.step()
# could have done manual gradient update:
# with torch.no_grad():
# params = params - lr * params.grad
losses.append(J.item())
accuracies.append(y.eq(l.detach().argmax(dim=1).cpu()).float().mean())
print(f"epoch {epoch + 1}", end=", ")
print(f"training loss: {torch.tensor(losses).mean():.2f}", end=", ")
print(
f"training accuracy: {torch.tensor(accuracies).mean():.2f}"
) # print two decimals
# validation loop
losses = list()
accuracies = list()
model.eval() # disables dropout/batchnorm
for batch in val_loader:
x, y = batch
batch_size = x.size(0)
# x: b x 1 x 28 x 28
x = x.view(batch_size, -1).to(device)
# 5 steps to train network
# 1 forward
with torch.no_grad(): # more efficient, just tensor no graph connected
l = model(x) # l: logits
# 2 compute objective function
J = loss(l, y.to(device))
losses.append(J.item())
accuracies.append(y.eq(l.detach().argmax(dim=1).cpu()).float().mean())
print(f"epoch {epoch + 1}", end=", ")
print(f"validation loss: {torch.tensor(losses).mean():.2f}", end=", ")
print(
f"validation accuracy: {torch.tensor(accuracies).mean():.2f}"
) # print two decimals
epoch 1, training loss: 1.25, training accuracy: 0.64 epoch 1, validation loss: 0.50, validation accuracy: 0.86
epoch 2, training loss: 0.44, training accuracy: 0.87 epoch 2, validation loss: 0.37, validation accuracy: 0.89
epoch 3, training loss: 0.36, training accuracy: 0.90 epoch 3, validation loss: 0.32, validation accuracy: 0.91
epoch 4, training loss: 0.32, training accuracy: 0.91 epoch 4, validation loss: 0.29, validation accuracy: 0.91
epoch 5, training loss: 0.29, training accuracy: 0.92 epoch 5, validation loss: 0.27, validation accuracy: 0.92
6 Store models¶
# just save model weights without structure
torch.save(model.state_dict(), "model_weights.pth")
model.load_state_dict(torch.load("model_weights.pth"))
model.eval()
/tmp/ipykernel_2351/2099193612.py:3: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
model.load_state_dict(torch.load("model_weights.pth"))
Sequential( (0): Linear(in_features=784, out_features=64, bias=True) (1): ReLU() (2): Linear(in_features=64, out_features=64, bias=True) (3): ReLU() (4): Dropout(p=0.1, inplace=False) (5): Linear(in_features=64, out_features=10, bias=True) )
# save whole model
torch.save(model, "model.pth")
new_model = torch.load("model.pth")
/tmp/ipykernel_2351/2474383404.py:3: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
new_model = torch.load("model.pth")