Lunch Time Python¶
25.11.2022: spaCy¶
spaCy is an open-source natural language processing library written in Python and Cython.
spaCy focuses on production usage and is very fast and efficient. It also supports deep learning workflows through interfacing with TensorFlow or PyTorch, as well as the transformer model library Hugging Face.
Press Spacebar to go to the next slide (or ? to see all navigation shortcuts)
Lunch Time Python, Scientific Software Center, Heidelberg University
0 What to do with spaCy¶
spaCy is very powerful for text annotation:
- sentencize and tokenize
- POS (part-of-speech) and lemma
- NER (named entity recognition)
- dependency parsing
- text classification
- morphological analysis
- pattern matching
- ...
spaCy can also learn new tasks through integration with your machine learning stack. It also provides multi-task learning with pretrained transformers like BERT. (BERT is used in the google search engine.)
import spacy
from spacy import displacy
if "google.colab" in str(get_ipython()):
spacy.cli.download("en_core_web_md")
nlp = spacy.load("en_core_web_md")
doc = nlp(
"The Scientific Software Center offers lunch-time Python - an informal way to learn about new Python libraries."
)
displacy.render(doc, style="dep")
displacy.render(doc, style="ent")
1 Install spaCy¶
You can install spaCy using pip:
pip install spacy
It is also available via conda-forge:
conda install -c conda-forge spacy
After installing spaCy, you also need to download the language model. For a medium-sized English model, you would do this using
python -m spacy download en_core_web_md
The available models are listed on the spaCy website: https://spacy.io/usage/models
Install spaCy with CUDA support¶
pip install -U spacy[cuda]
You can also explore the online tool for installation instructions.
2 Let's try it out!¶
nlp = spacy.load("en_core_web_md")
nlp("This is lunch-time Python.")
This is lunch-time Python.
doc = nlp("This is lunch-time Python.")
print(type(doc))
[i for i in doc]
<class 'spacy.tokens.doc.Doc'>
[This, is, lunch, -, time, Python, .]
t = doc[0]
type(t)
spacy.tokens.token.Token
t.ent_id_
''
displacy.render(doc)
spacy.explain("AUX")
'auxiliary'
for t in doc:
print(t.text, t.pos_, t.dep_, t.lemma_)
This PRON nsubj this is AUX ROOT be lunch NOUN compound lunch - PUNCT punct - time NOUN compound time Python PROPN attr Python . PUNCT punct .
3 Pipelines¶

[source: spaCy 101]
The capabilities of the processing pipeline dependes on the components, their models and how they were trained.
nlp.pipe_names
['tok2vec', 'tagger', 'parser', 'attribute_ruler', 'lemmatizer', 'ner']
nlp.tokenizer
<spacy.tokenizer.Tokenizer at 0x7f0e469a3910>
text = "Python is a very popular - maybe even the most popular - programming language among scientific software developers. One of the reasons for this success story is the rich standard library and the rich ecosystem of available (scientific) libraries. To fully leverage this ecosystem, developers need to stay up to date and explore new libraries. Lunch Time Python aims at providing a communication platform between Pythonistas to learn about new libraries in an informal setting. Sessions take roughly 30 minutes, one library is presented per session and the code will be made available afterwards. Come by, enjoy your lunch with us and step up your Python game!"
print(text)
Python is a very popular - maybe even the most popular - programming language among scientific software developers. One of the reasons for this success story is the rich standard library and the rich ecosystem of available (scientific) libraries. To fully leverage this ecosystem, developers need to stay up to date and explore new libraries. Lunch Time Python aims at providing a communication platform between Pythonistas to learn about new libraries in an informal setting. Sessions take roughly 30 minutes, one library is presented per session and the code will be made available afterwards. Come by, enjoy your lunch with us and step up your Python game!
doc = nlp(text)
for i, sent in enumerate(doc.sents):
print(i, sent)
0 Python is a very popular - maybe even the most popular - programming language among scientific software developers. 1 One of the reasons for this success story is the rich standard library and the rich ecosystem of available (scientific) libraries. 2 To fully leverage this ecosystem, developers need to stay up to date and explore new libraries. 3 Lunch Time 4 Python aims at providing a communication platform between Pythonistas to learn about new libraries in an informal setting. 5 Sessions take roughly 30 minutes, one library is presented per session and the code will be made available afterwards. 6 Come by, enjoy your lunch with us and step up your Python game!
for i, sent in enumerate(doc.sents):
for j, token in enumerate(sent):
print(i, j, token.text, token.pos_)
0 0 Python PROPN 0 1 is AUX 0 2 a DET 0 3 very ADV 0 4 popular ADJ 0 5 - PUNCT 0 6 maybe ADV 0 7 even ADV 0 8 the DET 0 9 most ADV 0 10 popular ADJ 0 11 - PUNCT 0 12 programming VERB 0 13 language NOUN 0 14 among ADP 0 15 scientific ADJ 0 16 software NOUN 0 17 developers NOUN 0 18 . PUNCT 1 0 One NUM 1 1 of ADP 1 2 the DET 1 3 reasons NOUN 1 4 for ADP 1 5 this DET 1 6 success NOUN 1 7 story NOUN 1 8 is AUX 1 9 the DET 1 10 rich ADJ 1 11 standard ADJ 1 12 library NOUN 1 13 and CCONJ 1 14 the DET 1 15 rich ADJ 1 16 ecosystem NOUN 1 17 of ADP 1 18 available ADJ 1 19 ( PUNCT 1 20 scientific ADJ 1 21 ) PUNCT 1 22 libraries NOUN 1 23 . PUNCT 2 0 To PART 2 1 fully ADV 2 2 leverage VERB 2 3 this DET 2 4 ecosystem NOUN 2 5 , PUNCT 2 6 developers NOUN 2 7 need VERB 2 8 to PART 2 9 stay VERB 2 10 up ADP 2 11 to ADP 2 12 date NOUN 2 13 and CCONJ 2 14 explore VERB 2 15 new ADJ 2 16 libraries NOUN 2 17 . PUNCT 3 0 Lunch NOUN 3 1 Time PROPN 4 0 Python PROPN 4 1 aims VERB 4 2 at ADP 4 3 providing VERB 4 4 a DET 4 5 communication NOUN 4 6 platform NOUN 4 7 between ADP 4 8 Pythonistas PROPN 4 9 to PART 4 10 learn VERB 4 11 about ADP 4 12 new ADJ 4 13 libraries NOUN 4 14 in ADP 4 15 an DET 4 16 informal ADJ 4 17 setting NOUN 4 18 . PUNCT 5 0 Sessions NOUN 5 1 take VERB 5 2 roughly ADV 5 3 30 NUM 5 4 minutes NOUN 5 5 , PUNCT 5 6 one NUM 5 7 library NOUN 5 8 is AUX 5 9 presented VERB 5 10 per ADP 5 11 session NOUN 5 12 and CCONJ 5 13 the DET 5 14 code NOUN 5 15 will AUX 5 16 be AUX 5 17 made VERB 5 18 available ADJ 5 19 afterwards ADV 5 20 . PUNCT 6 0 Come VERB 6 1 by ADV 6 2 , PUNCT 6 3 enjoy VERB 6 4 your PRON 6 5 lunch NOUN 6 6 with ADP 6 7 us PRON 6 8 and CCONJ 6 9 step VERB 6 10 up ADP 6 11 your PRON 6 12 Python PROPN 6 13 game NOUN 6 14 ! PUNCT
Adding custom components¶
You can add custom pipeline components, for example rule-based or phrase matchers, and add the custom attributes to the doc, token and span objects.
Processing batches of texts¶
You can process batches of texts using the nlp.pipe() command.
docs = list(nlp.pipe(LOTS_OF_TEXTS))
Disabling pipeline components¶
To achieve higher efficiency, it is possible to disable pipeline components.
nlp.select_pipes(disable=["ner"])
4 Rule-based matching¶
# Import the Matcher
from spacy.matcher import Matcher
# Initialize the matcher with the shared vocab
matcher = Matcher(nlp.vocab)
# Add the pattern to the matcher
python_pattern = [{"TEXT": "Python", "POS": "PROPN"}]
matcher.add("PYTHON_PATTERN", [python_pattern])
doc = nlp(text)
# Call the matcher on the doc
matches = matcher(doc)
# Iterate over the matches
for match_id, start, end in matches:
# Get the matched span
matched_span = doc[start:end]
print(matched_span.text)
Python Python Python
5 Phrase matching¶
More efficient than the rule-based matching, can be used for finding sequences of words, and also gives you access to the tokens in context.
- Rule-based matching: find patterns in the tokens (token-based matching)
- Phrase matching: find exact string; useful for names and if there are several options of tokenizing the string
doc = nlp(
"The Scientific Software Center supports researchers in developing scientific software."
)
# Import the PhraseMatcher and initialize it
from spacy.matcher import PhraseMatcher
matcher = PhraseMatcher(nlp.vocab)
# you can also pass in attributes, for example attr="LOWER" or attr="POS"
# Create pattern Doc objects and add them to the matcher
term = "Scientific Software Center"
pattern = nlp(term)
# or use pattern = nlp.make_doc(term) to only invoke tokenizer - more efficient!
matcher.add("SSC", [pattern])
# Call the matcher on the test document and print the result
matches = matcher(doc)
for match_id, start, end in matches:
span = doc[start:end]
print(span.text)
Scientific Software Center
6 Word vectors and semantic similarity¶
spaCy can compare two objects and predict similarity:
text1 = "I like Python."
text2 = "I like snakes."
doc1 = nlp(text1)
doc2 = nlp(text2)
print(doc1.similarity(doc2))
0.9570476558016586
token1 = doc1[2]
token2 = doc2[2]
print(token1.text, token2.text)
Python snakes
print(token1.similarity(token2))
0.18009576201438904
The similarity score is generated from word vectors.
print(token1.vector)
[-1.2606 0.065898 6.0885 -0.22722 0.83154 0.41309 3.1979 -0.046191 -1.2829 -1.3479 1.7709 3.668 -2.0622 2.7155 -1.0578 -2.5758 2.4921 1.6091 -1.0377 3.0679 -1.4015 3.7073 1.9131 -0.57248 -2.6436 0.63337 -0.29285 -3.4357 -2.1266 1.7317 -5.3598 1.3803 -0.54765 0.35455 2.7631 -1.977 0.44758 -1.4725 2.8591 -2.1695 2.3519 -1.3073 -2.5832 -1.1488 -6.6438 -0.93801 0.56867 0.87114 -0.96782 -5.2648 0.94436 2.2771 1.1189 -0.34377 -2.5144 2.9963 -2.5062 2.1578 -0.67746 -1.0898 1.6241 3.6518 -3.1079 4.7306 -0.66454 2.7364 0.13306 -3.4212 1.3897 2.3435 -5.4255 1.9155 -1.7938 -0.3813 1.5523 0.10848 -2.3448 -1.336 2.8275 -1.1881 -2.0658 -1.704 -0.72433 1.1114 -0.59757 -5.9866 2.3778 -0.16238 -2.3423 -1.7955 -0.77142 0.068012 0.68761 0.67404 -4.4701 2.4112 -0.2604 -1.0389 2.1799 -1.8888 2.3248 -0.68885 0.90761 1.6504 -0.5866 -0.95308 -2.2514 0.26756 0.090679 3.9386 3.1946 1.1651 -2.867 1.3898 -0.50941 -0.89953 -6.4801 2.1745 -2.1203 0.55437 -1.3614 -3.2856 -2.1754 0.48878 -2.4629 0.15834 -4.2165 -4.2826 0.56998 0.082179 0.42306 1.7157 4.5706 -0.57897 1.6457 0.32642 -0.50926 1.0044 0.11967 -1.2308 2.1196 -1.0886 2.0302 -0.22822 2.1447 1.3428 1.7925 -0.91104 -1.5624 0.59617 -0.34208 5.2826 0.37967 -3.9622 -5.4539 -2.3045 1.7818 5.9382 0.95568 -2.4973 3.5077 2.3859 -0.41935 -1.8645 0.80334 -0.40924 -1.3111 0.90649 -1.2311 0.7847 1.3806 -0.37329 -5.5309 2.092 0.81443 0.097034 2.9104 0.34064 0.075322 -0.46475 0.17099 2.6546 -4.8524 -0.029789 0.64981 0.76909 -4.32 -6.5618 -0.37659 0.15436 2.5368 -0.17104 -0.14987 2.1709 -0.60606 6.0411 2.8818 2.8922 2.8558 -0.61347 -4.4471 2.6216 -5.6342 2.1586 2.0838 -0.12496 -3.1686 -1.5929 4.5141 -0.060719 -3.2781 -1.5175 0.48335 3.9961 1.6667 1.6139 1.2288 -0.095046 0.52451 0.98974 2.4654 3.1082 -2.9114 2.9509 1.9835 -0.075264 4.079 -0.43975 0.70653 1.8881 -0.13128 -2.4122 0.37447 -0.086059 0.018365 -1.0378 1.9564 -0.089256 4.3107 -1.6252 -1.5946 -2.5387 -0.54987 0.83453 5.3653 1.2602 -1.3737 -5.2252 -0.61126 -2.4068 2.6474 -0.66264 -3.2214 -1.4838 -0.34186 2.418 2.1285 -2.8315 -1.4845 1.9585 1.3732 -0.83277 0.30195 0.050321 -0.14242 -2.96 2.3108 4.2398 -4.639 -3.6083 -0.97992 -2.9713 2.2687 0.02414 0.25454 -2.2333 1.933 1.6268 -3.3229 3.1813 0.17175 -1.6586 -0.12658 1.3129 1.3892 1.5215 2.4376 0.17856 -0.65205 0.72564 -0.92968 -3.0689 3.5688 1.8885 3.7389 1.9741 0.69516 -2.4315 -3.1602 2.8082 ]
Similarity can be used to predict similar texts to users, or to flag duplicate content.
But: Similarity always depends on the context.
text3 = "I hate snakes."
doc3 = nlp(text3)
print(doc2.similarity(doc3))
0.9609649512308942
These come out similar as both statements express a sentiment.
7 Internal workings¶
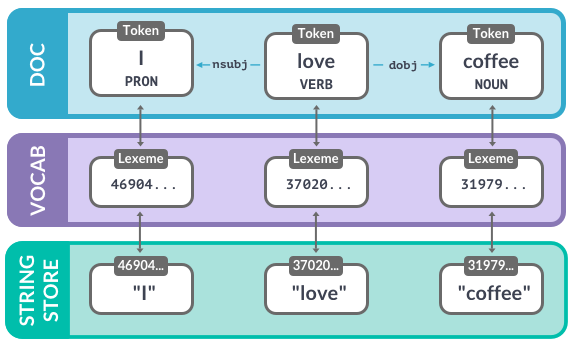
spaCy stores all strings as hash values and creates a lookup table. This way, a word that occurs several times only needs to be stored once.
nlp.vocab.strings.add("python")
python_hash = nlp.vocab.strings["python"]
python_string = nlp.vocab.strings[python_hash]
print(python_hash, python_string)
17956708691072489762 python
- lexemes are entries in the vocabulary and contain context-independent information (the text, hash, lexical attributes).
8 Train your own model¶
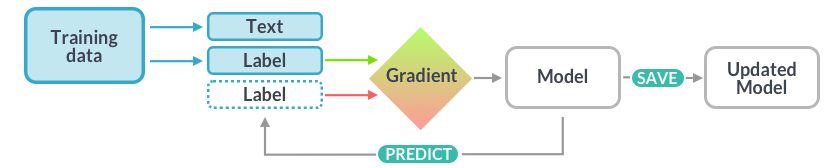 [source: spaCy online course]
[source: spaCy online course]
Training data: Annotated text
Text: The input text that the model should label
Label: The label that the model should predict
Gradient: How to change the weights
The training data¶
- Examples in context
- Update existing model: a few hundred to a few thousand examples
- Train a new category: a few thousand to a million examples
- Created manually by human annotators
- Use matcher to semi-automatize
Also need evaluation data.
Create a training corpus¶
from spacy.tokens import Span
nlp = spacy.blank("en")
# Create a Doc with entity spans
doc1 = nlp("iPhone X is coming")
doc1.ents = [Span(doc1, 0, 2, label="GADGET")]
# Create another doc without entity spans
doc2 = nlp("I need a new phone! Any tips?")
docs = [doc1, doc2] # and so on...
Configuring the training¶
The training config.cfg contains the settings for the training, such as configuration of the pipeline and setting of hyperparameters.
[nlp]
lang = "en"
pipeline = ["tok2vec", "ner"]
batch_size = 1000
[nlp.tokenizer]
@tokenizers = "spacy.Tokenizer.v1"
[components]
[components.ner]
factory = "ner"
[components.ner.model]
@architectures = "spacy.TransitionBasedParser.v2"
hidden_width = 64
...
Use the quickstart-widget to initialize a config.
That's it! All you need is the training and evaluation data and the config.¶
python -m spacy train ./config.cfg --output ./output --paths.train train.spacy --paths.dev dev.spacy
After you have completed the training, the model can be loaded and used with spacy.load().
You can also package and deploy your pipeline so others can use it.
A few notes on training¶
- If you update existing models, previously predicted categories can be unlearned ("catastrophic forgetting")!
- Labels need to be consistent and not too specific
9 spaCy transformers¶
You can load in transformer models using spacy-transformers:
pip install spacy-transformers
Remember that transformer models work with context, so if you have a list of terms with no context around them (say, titles of blog posts), a transformer model may not be the best choice.
 [source: spaCy documentation]
[source: spaCy documentation]
transformer-based pipelines end in _trf:
python -m spacy download en_core_web_trf
10 Further information¶
spaCy demos¶
- You can explore spaCy using online tools
For example, the rule-based matcher explorer -
- or the spaCy online course.